Let's make an information Display Part 3: Deploying
The Development Environment
Fake API
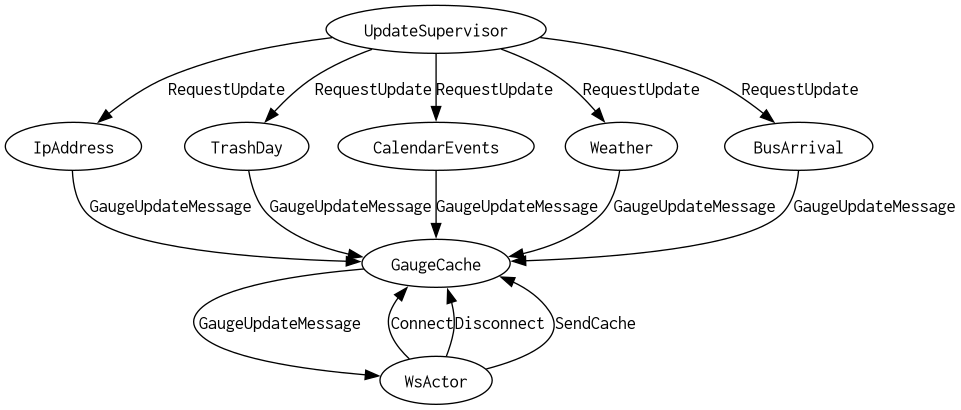
Several of our gauges involve making real requests to APIs. Ordinarily that's not a problem, but when debugging or iterating you can run up your usage very quickly.
The solution? Fake data!
We could just use static data, but what's the fun in that? This way we can tell when the backend gets updated.
pub trait Mock where Self: Sized, { fn get_one(rng: &mut ThreadRng) -> Self; fn get() -> Self { Self::get_one(&mut rand::thread_rng()) } fn get_several(rng: &mut ThreadRng) -> Vec<Self> { get_several(rng) } }
Here's the example for BusArrival:
fn get_one(rng: &mut ThreadRng) -> Self { let arrival = Local::now() + Duration::minutes(rng.gen_range(0..60)); BusArrival { arrival, live: rng.gen(), } }
You might notice Mock::get_several calls a function also named get_several.
This is for types like BusArrival that need preprocessing:
fn get_several(rng: &mut ThreadRng) -> Vec<Self> { let mut arrivals = get_several(rng); arrivals.sort_by_key(|v: &BusArrival| v.arrival); arrivals }
Traits in rust often behave a lot like Objects,
but here's one way they're very different:
If my implementation defines get_several,
there's no way to use the Mock implementation.
By breaking it out, we can call this default and then add our additional logic.
Serving the Mocks
We use a feature to enable these fakes:
[features] fake = ["den-message/mock", "dep:rand"]
Then when we start up, we just generate our values and seed our cache:
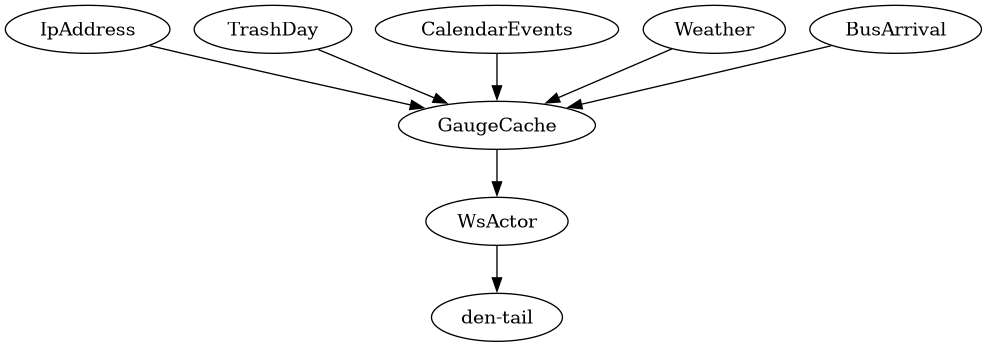
#[cfg(feature = "fake")] async fn init() { use den_message::*; use den_tail::cache::GaugeCache; let mut rng = rand::thread_rng(); let vars = vec![ GaugeUpdate::BusArrival(BusLine::get_several(&mut rng)), // etc ]; for var in vars { GaugeCache::update_cache(var).await.unwrap(); } }
If we wanted, we could schedule updates to be randomly generated later, too,
just by calling init in a loop with interval.
actix::spawn(async { let mut interval = actix::clock::interval(Duration::from_secs(1)); loop { interval.tick().await; init().await; } });
Trunk
Yew recommends trunk as a tool for development. It handles compiling, bundling assets, and serving webassembl applications. It even does automatic reloads when code changes.
Configurations, interestingly, come in the form of html files. Here's mine:
<!DOCTYPE html> <html lang="en"> <head> <link rel="stylesheet" href="https://fonts.googleapis.com/css?family=Overpass"> <link data-trunk rel="css" href="static/den-head.css"> <link data-trunk rel="copy-file" href="static/wifi_qr.png" </head> <body> </body> </html>
I make use of cargo-make to run the application more easily.
Here I run the frontend:
[tasks.serve_he ad] workspace = false command = "trunk" args = ["serve", "den-head/index.html", "--port", "8090", "--public-url=/static"]
The workspace = false is because, by default,
cargo-make will try to run serve_tail in every component directory.
Not what we want in this case.
And the backend:
[tasks.serve_tail] workspace = false env = {"RUST_LOG" = "den_tail=debug"} command = "cargo" args = ["run", "--features", "trunk-proxy,fake", "--bin", "den-tail"]
There's fake from before.
trunk-proxy does what it sounds like:
it passes through requests to / on the backend to Trunk.
here's what the index function looks like:
#[get("/")] async fn index(req: HttpRequest) -> Result<HttpResponse> { imp::static_("index.html", req).await }
Where imp is one of two backends.
When trunk-proxy is enabled, it uses actixproxy and actix-ws-proxy1
#[cfg(feature = "trunk-proxy")] mod imp { pub(crate) async fn static_(path: &str, _req: HttpRequest) -> Result<HttpResponse> { use actix_proxy::IntoHttpResponse; let client = awc::Client::new(); let url = format!("http://{}/static/{}", PROXY_HOST, path); log::warn!("proxying {}", url); Ok(client.get(url).send().await?.into_http_response()) } }
When it's not enabled, i.e. in production, it uses actixfiles instead:
pub(crate) async fn static_(path: &str, req: HttpRequest) -> Result<HttpResponse> { Ok(NamedFile::open_async(format!("static/{}", path)) .await? .into_response(&req)) }
The Backend Deploy
Let's talk about production.
When I first built this application, I deployed in a Modern Way. I had a Dockerfile, I pushed it to my Dockerhub account, and pulled it down to run it. But this had some annoying properties. For one, because it was public, I couldn't add any secrets to the file. And since the QR code for the wifi is secret I would've needed to generate the image at runtime instead of compile time.
Plus, it was just overkill. Instead, now I just build a tarball.
This uses the Cargo-make rust-script backend to create an archive, grab the files, and write them all out.
[tasks.tar] dependencies = ["build-all"] workspace = false script_runner = "@rust" script = ''' //! ```cargo //! [dependencies] //! tar = "*" //! flate2 = "1.0" //! ``` fn main() -> std::io::Result<()> { use std::fs::File; use tar::Builder; use flate2::Compression; use flate2::write::GzEncoder; let file = File::create("den-tv.tar.gz")?; let gz = GzEncoder::new(file, Compression::best()); let mut ar = Builder::new(gz); // Use the directory at one location, but insert it into the archive // with a different name. ar.append_dir_all("static", "den-head/dist")?; ar.append_path_with_name("target/release/den-tail", "den-tail")?; ar.into_inner()?.finish()?.sync_all()?; Ok(()) } '''
Then to deploy it, I just use ansible.
I copy the file over and extract it with unarchive:
- ansible.builtin.unarchive: copy: true src: '../den-tv/den-tv.tar.gz' owner: '{{ user.name }}' dest: '{{ dir.path }}' become: true register: archive
Set up a systemd service: #+
[Unit] Description="den TV service" [Service] WorkingDirectory={{ dir.path }} ExecStart={{ dir.path }}/den-tail User={{ user.name }} Environment=RUST_LOG=den_tail=debug [Install] WantedBy=multi-user.target
Then restart it:
- name: start service ansible.builtin.systemd_service: name: den-tv daemon-reload: "{{ unit.changed }}" enabled: true state: restarted become: true
It runs on a virtual machine on my NAS, so it's easily accessible over the network.
The Frontend Deploy
The frontend is served by, what else, a Raspberry Pi.

I planned to use cage to automatically start a full-screened browser.
But for whatever reason, on the version of Raspbian I'm running cage hard-crashes after a minute or two.
Instead, I'm just using the default window manager and a full-screened Chrome2.
I've got a wireless keyboard I can grab to make changes if need be,
but it's been rock solid.
Automatic Reloads
There's one last trick: We know how to restart the backend when the code changes, but what about the frontend?
Take a look at build.rs from den-message:
const ENV_NAME: &str = "CARGO_MAKE_GIT_HEAD_LAST_COMMIT_HASH"; fn main() { println!("cargo:rerun-if-env-changed={}", ENV_NAME); let git_hash = std::env::var(ENV_NAME).unwrap_or_else(|_| "devel".to_string()); println!("cargo:rustc-env=GIT_HASH={}", git_hash); }
We use an environment variable exposed by cargo-make to capture the git hash.
It's stored in den-message:
pub const VERSION: &str = env!("GIT_HASH");
When the backend server receives a new connection, it sends a hello message:
fn send_hello(ctx: &mut WebsocketContext<Self>) { let hello = &DenMessage::Hello { version: den_message::VERSION.to_string(), }; match serde_json::to_string(hello) { Err(e) => error!("Failed to encode Hello: {:?}", e), Ok(msg) => ctx.text(msg), } }
Because den-message is shared between the backend and frontend,
it's also available on the websocket side.
When we receive the Hello message, we check to see if it matches the version the webassembly was compiled with:
fn update(&mut self, ctx: &yew::Context<Self>, msg: Self::Message) -> bool { match msg { // snip Ok(DenMessage::Hello { version }) => { if version != den_message::VERSION { gloo_console::log!("reloading for version mismatch"); let _ = window().location().reload(); } } } true }
If the backend sends a different version, the page knows to reload. Since the backend serves the frontend, the next reload will always have the newest version.
The coolest effect of this is that I can sit at the kitchen table and run ansible-playbook to ship a new version.
Then a few seconds later, the screen on the other side of the table automagically refreshes and shows me my changes.
Pretty snazzy!
Conclusion
I hope you've enjoyed this series, or at least found it informative. This project is absolutely over-engineered, and over-complicated. It took me multiple weeks to build, but I learned a ton. Along the way my searches led me to a lot of random folks' blog posts about things they've done. I hope if nothing else, these posts show up in someone's search results and help them solve a problem.
Thanks for reading, and feel free to get in touch!



![The bus gauge with [26] in blue, and the background in lighter blue. several numbers are listed below.](./static/den-tv-styled-bus-gauge.png)